
One of the many reasons why the USPTO’s DOCX initiative presents professional liability risks arises from USPTO’s use of an ever-changing “black box engine” to render DOCX files into PDF files. The black box engine is by now up to at least version 19.
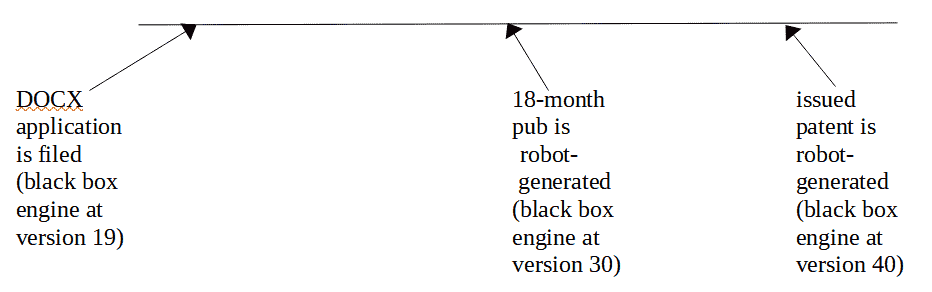
The timeline above offers a reminder of one of the ways that the ever-changing nature of the USPTO’s black box DOCX-to-PDF rendering engine puts applicants and practitioners at risk.
We all know that DOCX is not a human-readable computer file format. The only way that you or I as a human being can “view” a DOCX file is by opening it with some word processor another and seeing how the content of the file gets rendered into human-readable form. This rendering might happen on the screen of the word processor. This rendering might happen when the word processor prints the content to a printer.
We all also know that it is commonplace to run into situations where three human beings, at different locations, opening the same DOCX file using three different word processors on the same day, can see three non-identical renderings on their computer screen or on their printers. Likewise the USPTO’s own black box engine might render things differently on a particular day than some user’s word processor. This illustrates the professional liability risks across different locations on some particular day.
A moment’s thought prompts a realization that the professional liability risks extend not only across locations on some particular day, but also extend over time. If you were to open a particular DOCX file today, using today’s version of (say) the Microsoft 365 cloud-based word processor, you might see one rendering on your screen. But if you were to open that same DOCX file a year from now (after some 365 days had passed), it is impossible for you to know for certain that the rendering on your screen would be identical. The software is cloud-based and would likely have changed from time to time over those 365 days.
Which brings us around to the USPTO’s proprietary and ever-changing black box engine for rendering DOCX files into human-readable form. How do we know it is ever-changing? Director Kathi Vidal revealed this on her blog on December 19, 2022. She said:
We’ve heard from some of you that you are concerned the validated DOCX version or the USPTO-generated PDF version may contain a discrepancy. Though we saw discrepancies in earlier versions of the tool, we considered your feedback and have updated the tool accordingly. It is now at a very advanced stage (version 18).
(emphasis added.) The engine changed again in March of 2023, bringing the version number up to at least 19. So let’s look at a timeline. Let’s suppose you file your DOCX patent application on a day when the USPTO’s black-box rendering engine happens to be at version 19.
This prompts a realization that the USPTO’s black-box rendering engine might be at version 30 when the USPTO uses the engine to generate the 18-month publication of your DOCX patent application. And the USPTO’s black-box rendering engine might be at version 40 when the USPTO uses the engine to generate the issued patent from your DOCX patent application.
This means that no matter how closely you try to proofread the rendering by the USPTO’s engine on the day you file your DOCX patent application, this is of no help in predicting whether some later version of the USPTO’s rendering engine would render your DOC patent application.
This means that even if you look at the 18-month publication by the USPTO of your DOCX patent application, and maybe do not see any rendering problems, this this is of no help in predicting whether the later version of the USPTO’s rendering engine in use at the time of issuance of your DOCX patent application might nonetheless introduce errors into your issued patent.
While I do agree with many of Carl’s concerns, those generally apply to PDF files just like DOCX files. I have dozens of PDF files that open just fine on my computer, but EFS Web will accuse them of not being a PDF and straight out reject them. Interestingly, PatentCenter accepts the same file. Similarly, the PDF that ends up in the image file wrapper is clearly not the same fike an applicant uploaded but rather the USPTO’s rendition thereof. I have had PDF files that appeared completely blank in IFW, even though the showed fine on my computer.
That said: I do like the “black-box” accusation. There is no reason why the USPTO must keep the source code of its DOCX processor that we paid for with our fees secret. I would love for the office to maintain the code on GitHub for anyone to inspect and propose improvements. It would go a long way in building trust and help identify bugs (and workarounds).
It was maybe two years ago that I spent time on the telephone with the Acting Commissioner for Patents and with an Assistant Commissioner, telling them that if they wished to earn the trust of the applicants, they would need to publish the source code for their black box rendering engine. This would, of course, include maintaining a change log.
As best I can tell, this fell on deaf ears.
Just wondering: Would it make sense to submit a FOIA request for the source code? Best I can tell the source code would not fall under any exemption and fit squarely within what FOIA request are supposed to achieve: Help us understand how our government works.
Axel, in fact, the PDF standard, by design, provides “what you see is what you get.” The concerns Carl raises about DOCX therefore do not apply to PDF.
As explained in the PTO’s “Legal Framework For Patent Electronic System” document, the PTO converts pdf documents filed in EFW-Web to tiff image files and stores those files. The EFS-Web does NOT store the pdf file you uploaded and submitted. See https://www.uspto.gov/sites/default/files/documents/2019LegalFrameworkPES.pdf. (Unless of course you refer to documents save to the SCORE database, which are the documents you uploaded and submitted.)
Note that the “Legal Framework For Patent Electronic System”, by its terms, does not apply to Patent Center.
I agree that “We all know that DOCX is not a human-readable computer file format. The only way that you or I as a human being can “view” a DOCX file is by opening it with some [programme on a computer] and seeing how the content of the file gets rendered into human-readable form. This rendering might happen on the screen of the [computer]. This rendering might happen when the [computer] prints the content to a printer.” This is a very important point. It might be interesting to explore whose computer exactly matters if your computer and the USPTO’s computer render a file differently.
But this is the same for PDFs. If you change the extension from .docx to .zip, you can open the zip folder and open the XML files contained in it with Notepad, giving human-readable text. The words you typed can be seen in Notepad, with some XML code added, but the words are plainly there. That is not the case if you open a PDF file with Notepad. So in the event that MS Word disappears, you can still use Notepad (which I believe is universal and never changes?)
PDF viewing software might also differ 10 years in the future; at least newer versions might be available then. I don’t know if the difference is that the USPTO uses off-the-shelf software for handling PDF and special custom software for rendering .docx? And do we know for sure that the PDF rendering software used by the USPTO in 2030 is the same as now? Or is the PDF only rendered upon filing, and after that, the TIFF files are authentic?