Just when you thought you were completely familiar with the USPTO e-commerce systems, you realize you were missing something important for all these years. Yes, it turns out that for all of these years, the Public PAIR system has been used for filing of patent applications. See this USPTO News Brief published today, which is quoted at right. Continue reading “PAIR was for filing patent applications?”
Hello readers. Have you filed any patent application (PCT or otherwise) in recent days using a sequence listing that you created using version 2.1.0 of the WIPO Sequence software? If so, then this blog article is a must-read for you and there are some action steps for you.
Never until today had I seen a pickup truck that lacked a grille. Indeed over the years I had come to realize that motor vehicles differ from one to the next in the “gapingness” of the openings in the grille. Motor vehicles that are more, shall we say, manly, tend to have grilles with larger and more gaping openings. And here is an otherwise presumably extremely manly Ford pickup truck, but with … wait for it … no grille at all. There is only a sort of decorative panel in its place. Who can guess where I am going with this? What vehicle is this? Continue reading “A pickup truck with no grill?”
(Update Monday July 11. The USPTO status page now admits that these systems are broken. “Users are intermittently receiving a 429 error code ‘too many requests’ when attempting to log into their USPTO.gov accounts to file in Patent Center, EFS-Web, TEAS and TEASi. The workarounds for this error are clearing the browser cache or switching web browsers. Other USPTO systems may also be affected. The USPTO technical teams are investigating.“)
It looks like Patentcenter and TEAS and PAIR and EFS-Web and MyUSPTO and Financial Managerare all broken just now.
The USPTO switched over to a new and different login system a couple of weeks ago, provided by a company called Okta. The way that you can see change this is that when you log in at any of the six above-mentioned USPTO systems, the throbber (Wikipedia article) looks very different from the way it used to look for the past decade or so. Now the throbber is a sort of hexagon made of blue dots, hovering over the words “signing in”, with corporate branding “Okta” in the lower right corner of the screen.
At right you can see a screen shot of the USPTO’s newly adopted throbber screen, which as I say first started showing up maybe two weeks ago.
For most of the past two weeks, the new Okta throbber screen seemed to work fine. But today (Saturday, July 9, around 10 AM Eastern Time) the throbber screen has been throbbing for maybe 45 seconds and then what pops up is the 429 screen that you see quoted at top right.
The practical consequence is that it is impossible to log in at Patentcenteror TEAS or PAIRor EFS-Webor MyUSPTOor Financial Manager.
When you get to the 429 screen, you see that “status page” is a link. I clicked on the link, and it brought me to a new page https://status.okta.com/ on which the Okta company uses lots of green check boxes to cheerfully explain that every one of their systems is operating normally.
The USPTO maintains what it misleadingly calls its USPTO Systems Status and Availability page. When some USPTO system does not seem to be working correctly, it is tempting to visit this page to see whether perhaps somebody at the USPTO has (a) noticed that the system is broken and (b) posted a message on this page to acknowledge that the system is broken. It is normally a complete waste of time to check this page, and today was no exception. Yes the page lists various scheduled maintenance activities that are set for today, but none of them involve any of the six systems mentioned in this blog article. And, predictably, the status page shows no indication that anybody at the USPTO has noticed that these five systems are broken just now.
Returning to the 429 screen quoted at top right, you can also see that “Go to Homepage” is also a link. I clicked on the link, and it brought me to a new page at the USPTO, inviting me to log in. I entered my user ID and clicked “next” and what popped up is a big red message “Unable to sign in”.
If you want to keep up to date on the status of the important USPTO systems, what is quite clear is that checking the USPTO Systems Status and Availability page is not the way to do it. The way to do it is to be a subscriber to the relevant listserv, for example the e-Trademarks listserv, the Patentcenter listserv, the PAIR listserv, and the EFS-Web listserv. Or, I suppose, to be a subscriber to my blog.
Yesterday (blog article) I reported half a dozen US trademark applications that had been filed as much as 2½ years ago and still did not have an Examining Attorney. Here are five more US trademark applications that were filed a long time ago and still do not have an Examining Attorney:
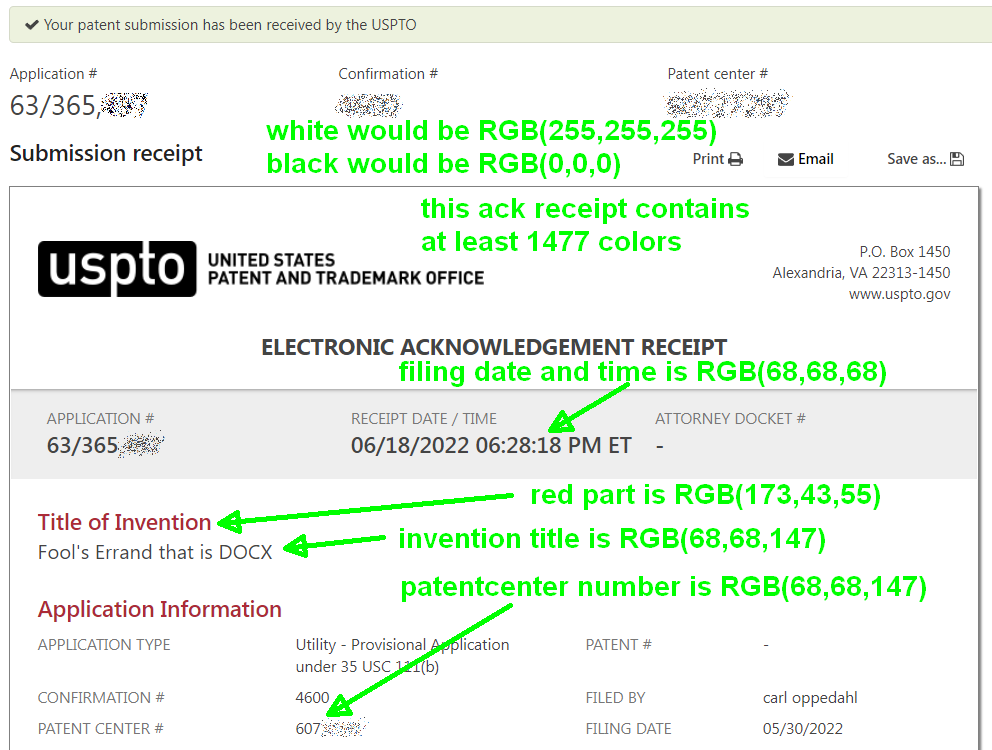
The Patentcenter developers continue to violate their own rules about how filers are supposed to format their documents. They do not just violate their own rules a little. They violate their own rules big time. The violations by the Patentcenter developers make life more difficult for applicants because it makes acknowledgement receipts nearly unreadable in IFW. (The Image File Wrapper (IFW) is a date-stamped, electronic record of the documents in the file and it is the primary source for viewing the entire history of a patent application. Integrity of IFW is essential.) The violations by the Patentcenter developers make life more difficult for the filer of a third-party submission of prior art, because by the time the Examiner sees the third-party submission, it is nearly unreadable in IFW. It means the Examiner is unlikely to give full consideration to the third-party submission. Continue reading “Patentcenter developers continue to violate their own rules big time”
As I explain in this blog article, “presentation copies” from the USPTO are not very good from a “suitability for framing” point of view. But what is much worse is that “presentation copies” are going to cause harm to the trademark community. The Trademark Office’s recent spotlight on “presentation copies”, and indeed the Trademark Office’s recent program of giving them away for free, will very predictably embolden some trademark owners in overstating the breadth of their trademark rights. The Trademark Office will be aiding and abetting the intimidation of parties who are not actually doing anything wrong but who are the target of overly broad cease-and-desist letters. Continue reading “Why a “presentation copy” from the USPTO is no good”
(July 11, 2022. Updated to provide a TSDR link for each application number. Still none of the applications has been given to an Examining Attorney.)
The USPTO reports a pendency of around six to seven months for newly filed US trademark applications. But there are quite a few trademark applications that were filed a lot longer ago than that, that still do not have an Examining Attorney. Here are some examples:
As you will see, the oldest one on this list was filed more than 2½ years ago and still does not have an Examining Attorney. I hope and trust that some reader of this blog article who works in the Trademark Office will pass along these six application numbers to whoever it is that is responsible for assigning Examining Attorneys to trademark applications.
It strikes me that this is the sort of thing that computers are supposed to be good at. How can it possibly be that the Trademark Office does not already have some automated process that runs, say, once a month, and generates a report like this? Such a report would permit the appropriate Trademark Office person to take corrective action (see 37 C.F.R. § 2.23(d) and TMEP § 108.03) by assigning an Examining Attorney.