
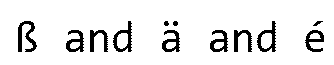 Seems to me that the Trademark Office people at the USPTO ought to have put software safeguards in place so that the Trademark Office could handle its own characters. The Trademark Office has not put such safeguards into place.
Seems to me that the Trademark Office people at the USPTO ought to have put software safeguards in place so that the Trademark Office could handle its own characters. The Trademark Office has not put such safeguards into place.
To take a recent example, look at the mailing address for the application in this case: https://tsdr.uspto.gov/documentviewer?caseId=sn98346158&docId=APP20240108143339&linkId=5#docIndex=4&page=1 . The mailing address in the application as filed is:
Eper Straße 45 – 47
The “ß” character, as anyone who studied the German language in junior high school knows, is the “scharfes S” (Wikipedia article).
But now let’s look in TSDR Status using Chrome, and what we see is:

Another option would be to look in TSDR Status using Firefox, and what we see is:

In Notepad, what we see is:
![]()
It turns out that for reasons known only to the Trademark Office, the Trademark Office stores the perfectly readable “ß” character in hexadecimal characters as “C382C29F”. The “C382” when interpreted as a UTF-8 character is a LATIN CAPITAL LETTER A WITH CIRCUMFLEX or “Ô. The “C29F” cannot be interpreted as a UTF-8 character. The fact that “C29F” literally cannot be rendered at all (as UTF-8) leads to various coping mechanisms by various end-user rendering software. As quoted above, Chrome renders the “C29F” as a blank rectangle. As quoted above, Firefox simply skips over the “C29F” and does not render it at all. Notepad renders the “C29F” as a box with a question mark in it, as you can see quoted above.
There is a way to store a scharfes S in UTF-8, namely as “C39F”. And you can see the “C39F” tucked away (incorrectly by the Trademark Office) inside the “C382C29F” hex string. There is also a way to store a scharfes S in Unicode, namely as U+00DF. But the Trademark Office did not store the scharfes S correctly in either of those two standardized ways.
If one were to go to the trouble to point out this coding error by the Trademark Office, doubtless what would happen next is “blame the customer”. The USPTO person, responding to this situation, would try to say that the customer somehow ought to have known not to paste the “ß” into the field of the TEAS form when filing the trademark application. But that dog won’t hunt. If indeed the “ß” character was not supposed to be pasted into that field of the TEAS form, then the competent coder, coding that part of the TEAS form, ought to have flagged this as an improper input, sort of like improperly trying to put the letter “A” into a field for a purely numeric Zip code. Any competent coder would know how to flag this using, for example, a “regular expression” (Wikipedia article) or “regex”. But having failed to flag the “ß” character as improper, the competent coder was duty-bound to store the “ß” character properly so that it would render in TSDR as a “ß” character.
You might think that by now we have fully discussed the mistakes made by the Trademark Office coder in his or her handling of this trademark application, but no. Our attention shifts slightly downward on the page in TSDR to the place where we are told the “legal entity type”.
When this trademark application was filed in the TEAS form, the filer selected the legal entity type from a drop-down list of Trademark-Office-approved entity types. The filer selected “gesellschaft mit beschränkter haftung (GmbH)” from the drop-down list. You see the “lower case a with an umlaut” in this Trademark-Office-approved entity type.
The Trademark Office coder chose to store the “ä” character as the hexadecimal string “C383C2A4”. This poor choice prompts Chrome to render the string as “ä” which is LATIN CAPITAL LETTER A WITH TILDE followed by a generic currency sign (Wikipedia article), also sometimes called a “scarab”. Firefox and Notepad also render the string as “ä”.
There is a way to store an a with umlaut in UTF-8, namely as “C3A4”. And you can see the “C3A4” tucked away (incorrectly by the Trademark Office) inside the “C383C2A4” hex string. There is also a way to store an a with umlaut in Unicode, namely as U+00E4. But the Trademark Office did not store the “a with umlaut” correctly in either of those two standardized ways.
If one were to go to the trouble to point out this coding error by the Trademark Office, once again what I expect would happen next is “blame the customer”. The USPTO person, responding to this situation, would try to say that the customer somehow ought to have known not to select “gesellschaft mit beschränkter haftung (GmbH)” from the drop-down menu of Trademark-Office-approved legal entity types. But that dog won’t hunt. The filer did not paste the “ä” character into a TEAS form field. The filer merely selected something from a Trademark-Office-approved drop-down list of approved entity types. Having invited the filer to select the legal entity type that happened to have an “ä” in it, the competent coder was duty-bound to store the “ä” character properly so that it would render in TSDR as a “ä” character.
One could imagine any of three ways for the Trademark Office coders to clean up their mistakes here.
-
- A first clean and elegant way would be to decide that going forward, characters will be stored in Trademark Office systems as Unicode characters. The scharfes S would get stored as U+00DF and the a with umlaut would get stored as U+00E4. The many other standardized Unicode characters could likewise get stored in Unicode format.
- A second clean and elegant way would be to decide that going forward, characters will be stored in Trademark Office systems as UTF-8 characters. The scharfes S would get stored as C39F and the a with umlaut would get stored as C3A4. The many other standardized UTF-8 characters could likewise get stored in UTF-8 format.
- A third way, which would be basically giving up and ducking the true failures, would be to use a regex (or some other more crude coding method) to test for a scharfes S or an a with umlaut in the user input in the TEAS form, and puking on it. An error message would get displayed. This third way would require the USPTO to be diligent in the setup of its drop-down lists so as to eliminate for example “gesellschaft mit beschränkter haftung (GmbH)” as a permitted entity type for a German entity.
Similar problems surely lie in wait to be discovered. I see for example an application number 98679279 that got filed recently in TEAS. In this application, the filer selected a legal entity type, from a drop-down list of Trademark-Office-approved entity types, of “société par actions simplifiée (sas)”. Yes, we see the accent-acute diacritical marks that everybody learns about when they take French class in junior high school. And we know to brace ourselves for the coding mistakes. We see that the Trademark Office coders have butchered the diacritical marks so that by the time they are rendered in TSDR, it looks like this:
société par actions simplifiée (sas)
Each “e-with-acute-accent” character gets stored wrong, so that ordinary user apps render it as “é”.
What really matters, I suppose, is what will happen some months or years from now when the Trademark Office generates the official Certificate of Registration. In the registration certificate, will the Trademark Office render the “e-with-acute-accent” character as “é”? Nobody knows!
I wonder which of the three ways the Trademark Office will select to clean up its coding errors. And I wonder whether the Trademark Office will do me the courtesy of letting me know when they do the cleanup.