
I imagine for most people, a file server is not the sort of thing that you have warm and fuzzy feelings about. But hear me out.
We have half a dozen file servers at our firm. Some are in the office. Others are at various remote locations. A cloud backup configuration continuously backs up the main file server in our office to corresponding file servers in remote locations. This means if our office were to get struck by a meteorite and destroyed, we could turn to any of the remote servers and we would have all of our saved files as of maybe sixty seconds prior to the meteorite strike.
Each server also uses RAID 1, which mirrors the information in the server on two hard drives. This way if either hard drive were to crash, the other drive would, it is hoped, continue to provide have all of the saved files.
Having said all of this, the whole point of this set up is to minimize how much harm would flow from a failure of a hard drive in one or another of these file servers. We have each file server set up so that it monitors various things about its hard drives. And if there is some early warning sign that a particular drive might be acting flaky, we receive a monthly report with this information.
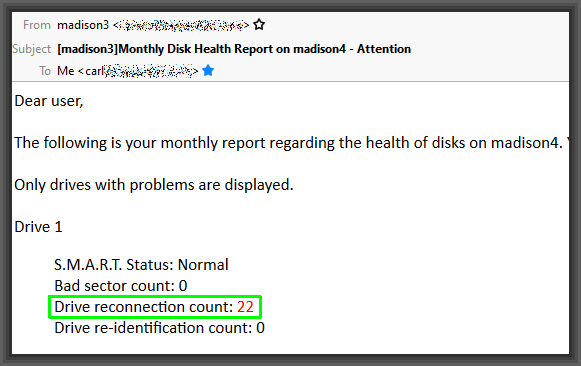
Here you can see an actual reporting email message, one that arrived two days ago on December 1, 2020. It tells me that for drive number 1 in a server called Madison, there have been some “drive reconnections”. Normally the count of drive reconnections would be zero, but in this case the undesirable event of a “drive reconnection” happened 22 times during November of 2020.
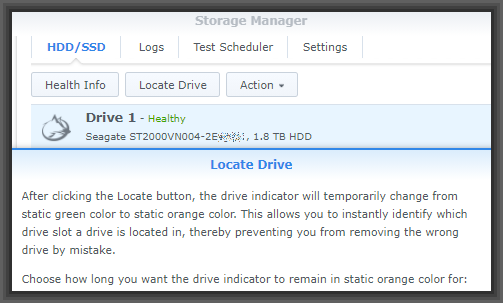
So this permitted us to order up a replacement hard drive. It arrived yesterday. So today I went to that server. I unlocked the cage which contains this server among others. I went to the web-based management page for this server and I clicked on “Locate Drive”. I cast my eye over the various servers in the cage, looking for the one with the orange blinky light. That told me which server is the one that is going to need the replacement of a drive.
I also noted which drive number in that server it was.
This file server permits what is called “hot swapping”. You don’t need to shut down the server to deal with a drive replacement activity such as this. I was able to simply pull out the drawer for the troubled hard drive (the one indicated by the orange light) while the server was running. I then pulled the bad hard drive out of its tray, and dropped a brand-new drive into the tray. I slid the tray back into the server. I went back to the web-based management page for this server, and I clicked to “rebuild” the RAID 1 array of which the troubled drive had been half.
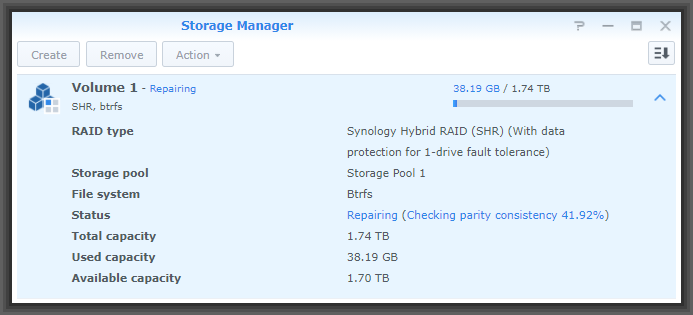
What then happened is that in a fairly automatic way, the file server operating system ran through various steps to rebuild the RAID 1 array. The first thing the system did was to run a detailed hardware check of the failed drive. Then it started copying all of the data from the (remaining) healthy drive onto the newly installed brand-new drive. As of right now the copying process has been running for maybe three hours, and around 42% of the data have been copied from the old healthy drive onto the brand-new drive.
One really nice thing about the “hot swapping” is that the web sites and other systems that rely upon this file server had continuous service provided to them. For example there are web sites that members of the public might visit, that rely upon this server. Those web sites continued to function in an uninterrupted way through the entire duration of today’s “hot swap”. And there is an intranet web site that we use within the firm for certain categories of information, and that web site continues to function in an uninterrupted way during this “hot swap”.
Of course during this rebuilding time, the performance of the drive system is poorer than it usually is. The hard drives are not only responding to normal service needs from users and other systems, but are also having to give quite a bit of their bandwidth over to the process of copying data from one hard drive to the next. The web sites that I just mentioned might take half a second to load instead of a quarter of a second, for example.
This period of poor system performance and poor web site performance will end in maybe four more hours.
Back to the warm and fuzzy feeling. I feel warm and fuzzy that the file server would give me advance warning like this. It permits me to swap out the hard drive that is looking like it might fail some day, right now, at a time when it has not yet actually failed. Maybe this will prevent our having to deal with a drive failure at all.
What kinds of feelings do you have for your file servers? Please post a comment below.
6 distributed replicating file servers! It sounds like you have more redundant backups than NORAD!
I have one file server storing the data set, 3 drives running daily, weekly, and monthly backups of the file server data set, and one commercial end-to-end encrypted cloud service performing real-time replication of the data set. I also have SQLBackupAndFTP periodically (daily) backing up the SQL database, and that backup of the SQL database is contained in the data set, that is part of the other periodic backups.
Since this is RAID 1, if you had let the failing drive go to failure, the result would have been the same, since the system would have marked the bad drive as having failed and continue serving data from its mirror, until you installed the replacement drive. Still, preemptive replacement upon warning is nice.
And, of course, there is still the potential for data loss should the mirror drive fail before the re-mirroring is complete.
Whatever the PTO did, check all your dates in Private PAIR. All dates (filing, priority, publication, issuance) are exactly one day off.
Saw that too. They still haven’t fixed after reporting date errors in multiple applications when dates were fine just two days before to Electronic Business Center.. All wrong dates for the PTA calculation screen too.