
As most readers know, a RAID system makes use of two 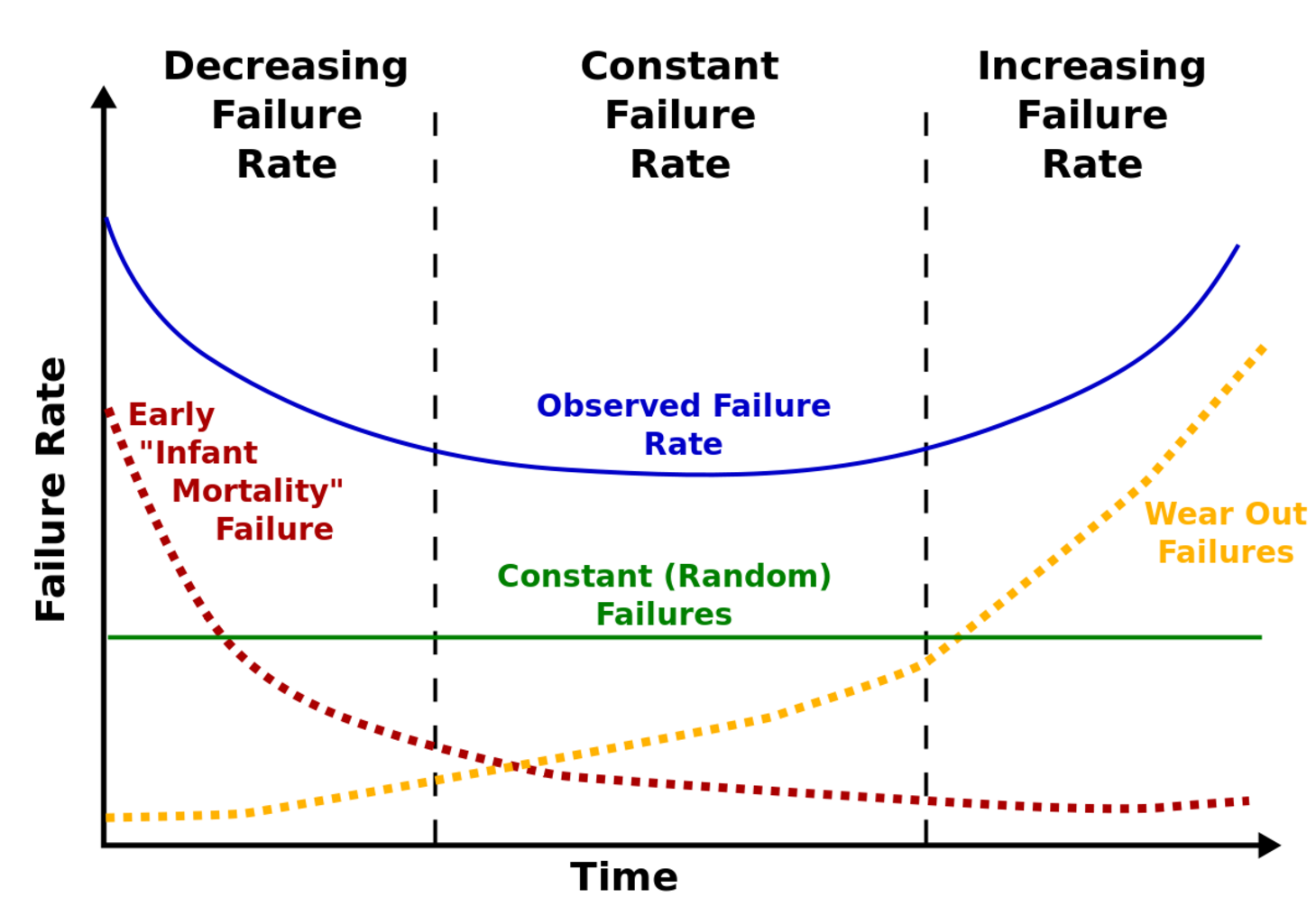 or more hard disk drives to provide a very reliable network-attached storage system. In a sophisticated way, the system stores information redundantly across two or more drives. If any one drive were to fail, the system would be able to continue in its normal function using the remaining drive or drives. Importantly, no data would be lost. This article talks about how you might pick the hard drives that you would plug into your RAID system.
or more hard disk drives to provide a very reliable network-attached storage system. In a sophisticated way, the system stores information redundantly across two or more drives. If any one drive were to fail, the system would be able to continue in its normal function using the remaining drive or drives. Importantly, no data would be lost. This article talks about how you might pick the hard drives that you would plug into your RAID system.
Our favorite RAID systems are the kind that distribute the saved data across four drives. If any one drive were to fail, the remaining three drives keep everything working with no loss of data. It is thus important to keep a spare drive or two around at all times. That way, if one drive were to fail, we could swap out the bad drive, put in a good drive, and the RAID system would rebuild itself automatically and we would once again have our redundancy and reliability.
One very nice thing about most RAID systems is that they keep an eye on the performance of the individual drives. This permits a bit of early warning that a particular drive is being a bit flaky. Not so bad that the drive has failed, but a warning that maybe it is going to fail some time soon.
Each individual drive in a RAID system will have its own MTBF (mean time before failure). With ordinary drives, the MTBF might be 3 or 5 years. But you can pay extra for a so-called “NAS” drive. It will have an MTBF of maybe 100 years.
A 4 terabyte drive might cost $111. An otherwise similar 4TB drive that calls itself NAS might cost $170.
When you are picking drives for your RAID system, the usual precaution is to pick drives made by different companies, or at least drives made a very different times. The idea is that if all of the drives had been made by the same company at the same time, there is the risk of some common failure mode that would make it more likely that two drives might fail at the same time. When I am ordering up such drives on Amazon I will order only one drive at a time and on separate days so that no two drives would be in the same box and could accidentally get dropped in transit in the same way.
The commonly followed model for device reliability is the so-called “bathtub curve“, shown above. The assumption is that early in the service life there might be some infant mortality. Then failures would diminish. After some time, failures would again be observed. Part of what you are paying for when you pay the higher price for a NAS drive is, perhaps, that the right end of the curve is much further in the future — 100 years rather than 5 years, perhaps. And maybe part of what you are paying for with a NAS drive is that some testing and screening happens after the drive is manufactured, to try to catch some of the infant mortality before the drive gets sent to the store for purchase by the customer.
What prompts today’s posting is some recent experience in our office with some NAS drives.
One of our RAID systems has been in service now for about fifteen years, and it has four drives. We try to track things pretty closely, and we find that two of the four drives have been in service for the life of the system. A third drive has needed replacement once in fifteen years, about five years ago. A fourth drive needed replacement about a year ago. We replaced it with a NAS drive.
When I say a drive “needed replacement” I mean that it started reporting disk errors, which prompted us to replace it. In this particular RAID system we have not had a drive fail completely.
Anyway what is a bit interesting and puzzling is that the drive that we plugged into the fourth pay a year ago, despite being a NAS drive that ought to have lived forever, is that it started being flaky just a couple of months later. So we pulled it out of service and swapped in a new NAS drive. After a few months it, too, started being flaky.
It seems sort of counter-intuitive that the NAS drive would fail much sooner than a cheapo non-NAS drive.
Of course one thing is the NAS drives may have a more sensitive error reporting mechanism. A very slight deviation in the NAS drive might get reported to the RAID system as a disk error, where a non-NAS drive maybe would not even count that slight deviation as a disk error at all.
These NAS drives have much longer warranties than non-NAS drives. Three or five years typically. Each of these failed NAS drives, I have sent in for warranty replacement and the manufacturer has replaced it without fuss.
Anyway, despite these two infant mortality experiences with the NAS drives, we plan to continue using NAS drives in our RAID systems going forward.
Carl,
Any chance it’s the actual bay and associated electronics for that bay that is the source of the problems? Perhaps
plug a “bad” drive into a different bay and see how it functions to confirm that it’s the hard drive.
Owen
Thanks for another great article, very nice graph, two quick comments though. First, RAID is not what I would call “reliable”, high availability, yes, but reliable, no. I say this because it is far too easy to destroy a parity RAID setup (i.e. RAID 5,6) or striped RAID (i.e. RAID 0) during reconfiguration events. There is also the issue of a single point of failure in the RAID controller card, assuming hardware RAID, which would be the standard for an enterprise class RAID as opposed to a home RAID, which might be software. Granted, the controller cards are probably more reliable than a typical hard drive.
Also, your article indicates you are running a RAID 5 on 4TB hard drives. You may want to transition to a double parity RAID setup that is tolerant of two disk failures (RAID 6). Although hard drives have continued to grow in size, the rate of encountering an uncorrectable disk error per GB read has remained relatively flat over the last decade. In a four disk RAID 5 setup comprising 4 4TB drives, the chance of encountering such an error, if memory serves me correctly, is about 50%, since the read error rate is about 50% per 10tb read. It may even be higher. Should such an error be encountered during a rebuild, as I’m sure you know, the rebuild will fail and the RAID lost.
Even more worrisome, if a drive fails or starts to fail around the 4-5 year or more mark, necessitating a rebuild, the stress induced by the rebuild, which could max out the drives for days at a time when rebuilding from a parity stripe, has been known to cause the other drives to fail, resulting in total data loss. This is the reason that a hot spare in such a setup is frowned upon; a hot spare will initiate a rebuild that could take out another disk before an administrator has had a chance to manually backup the array to an external drive, which is much easier on the drives than rebuilding from a parity stripe, especially if such backups are performed regularly and we are just interested in taking an incremental backup.
I just wanted to make clear to readers of this article that RAID 5 is basically dead and that the very significant chance of failure during a rebuild on modern, large arrays, combined with the inherent fragility of a RAID setup to begin with makes them a form of high availability storage (users can continue to be productive in the event of most common hardware failures), but is not a replacement for regular backups to, typically, external drives. Mirrored RAIDS, although space-inefficient (storage is halved with a two drive array), are much more reliable since the data is essentially simply duplicated across the array member drives and a rebuild is a simple copy of the good drive to a replacement drive as opposed to an algorithmic reconstruction as in parity RAID setups.
Thank you. Prompted by your comments, I think I am going to migrate this RAID server from RAID 5 to RAID 1. It does not have enough drive bays for RAID 6. Of course it used to be that drives actually cost a lot of money which I suppose is part of why I had picked RAID 5 for this server when it was placed into service ten or 12 years ago. Now that drives don’t cost much money, yes I think I will just buy some big drives and use two bays and run it as RAID 1.
Have you seen Backblaze’s periodic Hard Drive Reliability Reviews? It’s often interesting to hear about Backblaze’s experiences with their fairly large sample sizes (currently over 50,000 drives in their datacenter).
Here’s a link to the latest one: https://www.backblaze.com/blog/hard-drive-reliability-q4-2015/