
Suppose that there were a computerized system operated by a government agency where the paying customer pastes text characters into the system. Suppose the text were really important text that needs to appear at a later time in a prominent place on an official government document that bears a gold seal and the signature of the Undersecretary of Commerce.
The normal sensible thing would be for the text characters to get auto-loaded into the system that prints the official government document, right?
If you were going to make up a hypothetical example of what would be really stupid, your hypothetical example might be that after the customer pastes the text characters into the government system, the government agency flattens the text characters into a TIF image. And then the government agency carries out OCR (optical character recognition) to recover the text characters for the system that prints the official government document. And then the document gets printed, and the gold seal is applied, and then the Undersecretary of Commerce signs the document. In your hypothetical example it would be stupid to do it that way because the Office already was in possession of the actual characters, and anyway the OCR workflow costs money, and every now and then the OCR system might make a mistake. Of course it would be better to auto-load the text from the first computer system into the second computer system.
Well, you can’t make this stuff up. What the USPTO actually does is actually stupider than what you would make up. Yes, several hundred times per day, every time somebody pays an Issue Fee using the web-based issue fee payment system, the customer pastes text characters for the assignee name, the city of the assignee, and the “attorney, agent or firm” into a special page in EFS-Web. These text characters are all to be printed on the front page of the issued patent. And yes, after the customer clicks “submit” in EFS-Web, the USPTO flattens the information into a TIF image in IFW. But what you wouldn’t be able to make up is that USPTO does not even use OCR on those images. Just a few days after USPTO flattened the text into image format, a human being views the TIF image on a screen and hand-keys the information into the system for printing the US patent.
No, you can’t make this stuff up.
The way that the TIF image got generated by EFS-Web is that it was vector-rendered by a computer from text character information. This means the OCR would in fact be very close to 100% accurate if the USPTO were to use that path for recovering the characters. But USPTO does not even use OCR to recover the text from the images. The USPTO uses hand-keying by a human being to recover the text from the images.
Oh and the amount of time that passes during which this character information is temporarily stored in image format? Only a few days. The customer pays the issue fee on some particular day, and the Final Data Capture happens maybe a week later.
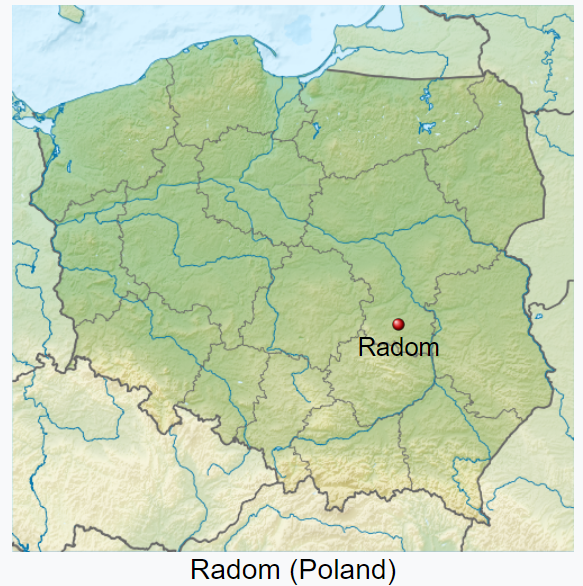
Let’s look at some real-life examples. The map above shows Radom, Poland, which I understand to be the fourteenth-largest city in Poland, having a population of over two hundred thousand people. Radom is also the home of a company (my client) that has over the years paid to the USPTO well over a quarter of a million dollars in Filing Fees, Search Fees, Examination Fees, Issue Fees, and Maintenance Fees relating to its inventions.
A few months ago I paid yet another Issue Fee to the USPTO on behalf of this client. I used the web-based Issue Fee system in EFS-Web. Here are the characters that I pasted into USPTO’s web-based form 85B:

And here is what USPTO printed on the front page of the patent that the USPTO issued a couple of weeks ago:
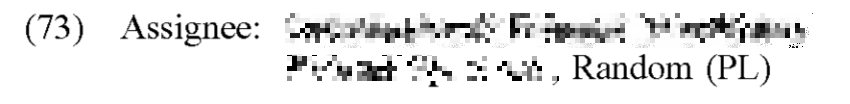
Yes, some human being saw the five letters “Radom” on a computer screen and typed the six letters “Random” into a keyboard.
Long-time readers of this blog will recall that I blogged with some enthusiasm about it when the USPTO first launched this web-based issue fee payment system in September of 2015. In November of 2015, I blogged with disappointment that it had become clear that USPTO was hand-keying the 85B information from the web-based Issue Fee form rather than auto-loading it.
During the four years that have passed, I would have hoped that maybe my November 2015 blog article would have prompted (or shamed) the USPTO into doing the non-stupid thing with the web-based Issue Fee payment form. The non-stupid thing would be to start auto-loading the text characters from the first computer system into the second computer system.
But even now in 2019, four years later, USPTO continues to take the text characters provided by the customer in the web-based form, and flatten them to TIF images, and then just a few days later the USPTO has a human being hand-key those same characters into a second computer system.
It pains me to have to say that this is not the first time that the USPTO caused this exact harm to this exact customer. In 2017 I paid an Issue Fee for this same client, and I used the web-based Issue Fee form. I pasted the five characters “Radom” into the web-based form. And the USPTO human being hand-keyed the six characters “Random” into the system for printing the US patent.
We will, of course, ask the USPTO to provide a corrected patent with the front-page information spelled correctly (not a mere certificate of correction) pursuant to 37 CFR § 1.322(b).
2 Replies to “Four years later, USPTO still discards characters and hand-keys images”