
(Updated to use a different inventor name.)
(This is trouble ticket number CP26.)
Patentcenter does a very poor job with diacritical marks. Alpha testers of Patentcenter have been reporting this problem for over a year now and it has not been fixed.
There is not merely some single way that Patentcenter does poorly with diacritical marks. There are multiple lapses in design and implementation quality. I will detail them one by one.
We start with a general notion that of course it is a Good Thing if a patent office makes it easy for a filer to provide information in computer-readable form, and then if the patent office auto-loads that information faithfully into USPTO’s systems. In general, the USPTO fails miserably at this seemingly easy Good Thing:
- The filer uses the web-based Form 85B to pay an Issue Fee, providing the Assignee information in computer-readable form. USPTO flattens the information into an image, and then hand-keys the Assignee information onto the front page of the issued patent.
- The filer uses the web-based Corrected ADS to provide updated bibliographic data, providing the updated bibliographic information in computer-readable form. USPTO flattens the information into an image, and then hand-keys the new bibliographic information into Palm.
- The filer provides a patent application in Microsoft Word format (misnamed by the USPTO as “DOCX format”). USPTO renders the word processor file into a PDF using a proprietary rendering engine, the behavior of which is unpredictable, and forces the filer to sign an adhesion contract agreeing that the PDF rendering will control even if the rendering engine makes mistakes.
The Patentcenter design defects are easy to see from this sequence of events.
The starting point of course is USPTO’s Form AIA/14, the ridiculously large (over one megabyte) PDF computer-readable fillable PDF form. I completed this form with the name of an inventor:

If you click to enlarge, you can see the kreska ukośna (stroke) in the letter ł which appears as the seventh letter in the inventor’s given name. This is pronounced sort of like the letter “w”. I suppose if a person gives up and attempts to select a Latin character instead, it might be the letter “L”. You can also see the kreska (which is graphically similar to the acute accent) in the letter ś, which appears as the third letter in the inventor’s family name. I suppose if a person gives up and attempts to select a Latin character instead, it might be the letter “S”.
The eventual resting place for this bibliographic data is Palm which is a four-letter acronym (“Patent Application Location and Monitoring”). Maybe Palm is able to store the stroke-L or maybe Palm is not able to store it. The actual answer is not very important here. The important thing is that if the designers of these systems were doing their jobs, they would validate the user inputs from the very start for things like this.
For example if Palm turns out to be incapable of storing a stroke-L, then (design mistake number 1) the Form AIA/14 should puke on the stroke-L the instant that I try to paste it into the inventor given name field. The fact of Form AIA/14 accepting the character rather than puking on it is, I submit, a promise by the USPTO that all downstream systems will accept the stroke-L. As will be seen, the USPTO breaks that promise.
The next step in Patentcenter is for the filer to upload Form AIA/14 into Patentcenter. I did that. Patentcenter then opens the ADS and extracts several fields and displays them on the screen for the filer to review. This is a very nice feature, much nicer than what EFS-Web does. This avoids the evil in EFS-Web of making you enter such things twice — once on a web-based screen and a second time through the uploaded ADS. And it permits you to check one last time to see whether for example by accident you uploaded the wrong ADS, for example an ADS from some other patent application. Here is what I saw on the Patentcenter screen when I did this:
Review the following information to make sure it is correct. In case of any errors fix the application data sheet and upload the file again.
![]()

So of course following the instructions, I did review the information to make sure it was correct. You can click to enlarge and you can see that the stroke-L and the accent-S each came through from the ADS into Patentcenter just fine.
The fact that the Patentcenter screen saying “review this information to make sure it is correct” shows the system accepting the character rather than puking on it is, I submit, a second promise by the USPTO that all downstream systems will accept the stroke-L. As will be seen, the USPTO breaks that second promise.
So then, relying on the Patentcenter preview of this bibliographic data which auto-loaded from my ADS, I e-filed the patent application. The first hint that the Patentcenter designers screwed up was in the Acknowledgment Receipt. In the Ack Receipt the system silently discarded two characters — the stroke-L and the accent-S. This is very poor system design. If designers are going to discard characters for any reason, the designers need to explicitly tell the user that they choose to do this. This is defect number three.
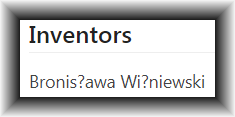
We then click around in the PAIR-like functions of Patentcenter with a goal of seeing what is actually in Palm. And what we see is this:
Well okay. In a way in could be said that this is less bad than what USPTO did in the Ack Receipt. At least on this screen the USPTO comes out and openly admits having mishandled two characters, replacing them on the screen with question marks.
The normal “USPTO way” of dealing with failures like this is “blame the user”. Instead of doing decent data validations at filing time, the USPTO normally ducks this and instead selects the most hard-to-find place on the USPTO web site and tucks away some obscure list of “acceptable characters” for this system or that system. Never mind that there is no single list of “acceptable characters”. There is the AC list for Form AIA/14 in and of itself. There is the AC list for Palm for inventor names. There is the AC list for Palm for street addresses. There is the AC list for characters permitted to be used in patent applications filed in Microsoft Word format (misnamed as “DOCX format”). There is the AC list for characters permitted in EPAS for street names for assignees, or for characters permitted in assignee names. No matter what, the usual approach is to hide away some list and then when some USPTO system turns out to be designed poorly (as illustrated here) the USPTO will blame it on the filer who (USPTO says) should have known better than to try to use the accent-S in the first place.
USPTO should get in touch with WIPO to learn how to do this sort of thing correctly. In ePCT, the system validates user inputs against permitted character sets at data entry time. If ePCT fails to flag a character is supposedly not permitted, then the character really does auto-load into all downstream systems without a hitch.
Have you checked to see whether the tool you’re using to load the AIA/14 form is properly storing the characters in the PDF document? I’m not blaming the user or excusing the behavior of the PTO systems. But ensuring the characters are properly stored, or if there are plural possible ways, exploring them, may be useful hints as to the mechanism of the failure and possible solutions.
There is no tool. You open the AIA/14 PDF form using free Acrobat. You paste the information into the form. You click file and save. Then you upload the PDF file into Patentcenter. There are no “plural possible ways” to store the characters into the form.
And anyway, after you upload the PDF file into Patentcenter, what happens next is that Patentcenter opens the PDF file and extracts the characters from the file. And then Patentcenter displays the characters on the screen for the human user to view. I quoted a screen shot of this in the blog article. So if there were any question whether somehow the user had “properly” stored the characters in the PDF file or somehow failed to “properly” store the characters into the PDF file, the step of looking at the screen in Patentcenter to see what characters Patentcenter extracted from the file is dispositive on this issue.
By “tool” I meant Acrobat reader or full Acrobat or whichever software you use. And the reason I suggest “plural possible ways” is that some diacritical-marked characters can be entered into computer software several different ways and can be stored in files using different character encoding schemes. (I don’t know if the Polish-alphabet characters are among them.) I’m thinking of characters that appear in, e.g., the ISO-8859-1, ISO-8859-2, Windows-1250, and Windows-1252 character sets that can still be entered in some software using whatever procedures were applicable in the days before Unicode was widely supported, and can also be entered using the corresponding Unicode code points. (Also, there are characters that have very similar appearance when displayed but have different code points.) Off-hand, I don’t know if Acrobat normalizes user-entered characters when storing form field data.
Hm. Well, it’s the job of the software designer to pay attention to whatever character encoding scheme is or is not going to be accepted for loading of characters into USPTO’s systems.
I simply used control-V to paste the characters into Acrobat, having copied them using control-c from some source document. I know absolutely nothing about how the creator of that source document created those characters. And it’s not my job to know.
Again I invite everyone to pay close attention to the fact that Patentcenter does extract those characters from the PDF file. And Patentcenter then does display those characters on the screen in Patentcenter for the human user to look at.
So if there is some issue about whatever character encoding scheme is or was used to store those characters, that issue is the job of some Patentcenter computer programmer to deal with. They extracted the characters from the PDF file, displayed them on the screen, asked me if the characters looked good on the screen. Yes they did look good on the screen. At that point my job is done. At that point it does not matter whether the characters were communicated by means of Unicode or stone tablets and chisels or Baudot or ASCII or EBCDIC. Not my problem, not after the Patentcenter software extracted them from the PDF file and rendered them on the screen for the human user to look at.