
It is recalled that one of the requirements for Patentcenter is that it is supposed to replicate the functions of Private PAIR. Only after this replication is complete would USPTO be entitled to pull the plug on Private PAIR.
The latest lapse, reported by alert listserv member Jill Santuccio, is in the metadata that Patentcenter uses when providing a multi-document download from IFW.
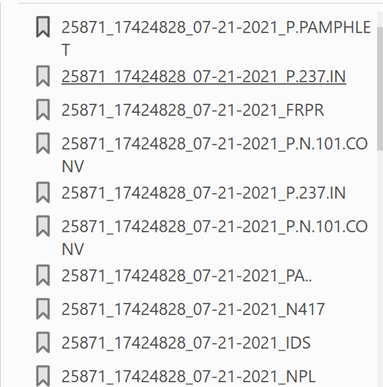
The screen shot above right shows the metadata appearing in the multi-document PDF file generated by Patentcenter. Documents are identified with cryptic codes like “P.237.IN”, preceded by strings of digits (in this case “25871_12424828”) that are of no help in distinguishing one document from the documents above it or below it.
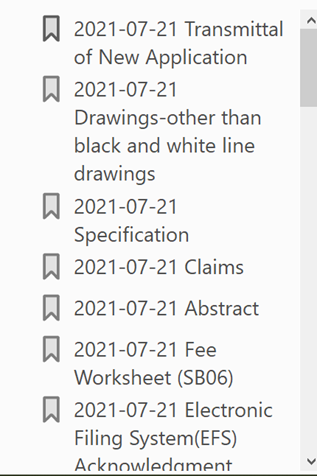
The USPTO’s own design standards for Patentcenter called for such features from Private PAIR to be replicated in Patentcenter. At right you can see how the multi-document download works in Private PAIR. Actual human-readable document descriptions appear in the PDF bookmarks. See for example “Drawings – other than black and white line drawings” which is human readable. And there is no clutter of random digits such as “25871_12424828” as seen in the screen shot from Patentcenter, top right.
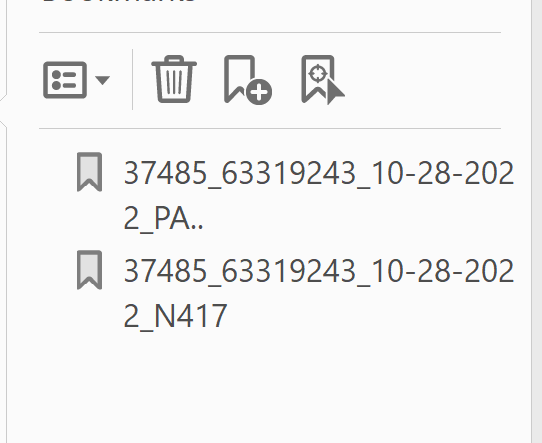
It might be helpful to compare the exact same documents as variously bookmarked in Patentcenter and as bookmarked in Private PAIR. At right you can see two documents as bookmarked by Patentcenter. The wholly unhelpful legends are “37485_63319243_10-28-2022_PA..” and “37485_63319243_10-28-2022_N417”.
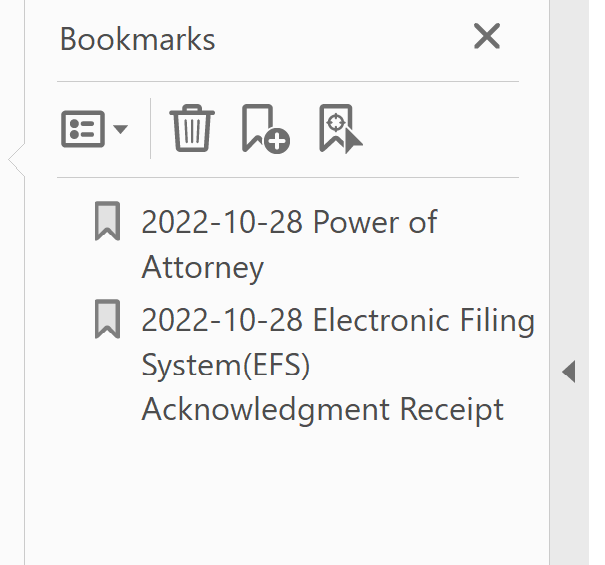
In Private PAIR, the developers got it right, as you can see here. The mysterious “37485_63319243_10-28-2022_PA..”, as reported by Patentcenter, is actually “2022-10-28 Power of Attorney”. The mysterious “37485_63319243_10-28-2022_N417”, as reported by Patentcenter, is actually “2022-10-28 Electronic Filing System (EFS) Acnowledgment Receipt”.
This is bug report CP93 at https://patentcenter-tickets.oppedahl.com. This is EBC ticket number 1-817731199 created on November 22, 2022.
It is also far more useful for sorting to have the dates at the beginning of the document description, with the year followed by the month and day..
Obviously the first portion of the metadata is the customer number and the second part the application number. But there’s no reason why that needs to be there. While I’m not that bothered by using the codes for the different file types instead of a text description, the text description would be better. And almost certainly there’s a table of codes and corresponding descriptions, so that switching from one to the other in the metadata should be almost as trivial as saying Column 1 instead of Column 2.
Richard is of course right: the digits are not random. But they are as practically unhelpful as if they were random. The customer number and application number _might_ be helpful as part of the file name for a multi-document PDF download. I would argue that the attorney docket number would be even more helpful.
But these numbers are constant for every single document in a multi-document PDF download, so adding them to every bookmark is completely unhelpful.
And here’s another thing: If you download the documents as a zip file, the date portion of the name is in yyyy-mm-dd format, but if you download them as a single PDF file, the date is in mm-dd-yyyy format.
That’s just absurd.