
It is completely sensible for a patent office to be interested in receiving characters rather than images when a patent application is being filed. There is the potential for everyone to benefit from successful submission of characters. But DOCX is not (and never can be) the right way to do it, since DOCX fails as a way to communicate patent applications reliably or accurately. See for example the letter that 82 patent practitioners sent to USPTO Director Vidal on December 28, 2022 urging her to read my paper called The Fools’ Errand that is DOCX. I recently gave another attempt to filing a patent application using DOCX, and this time, one of the “DOCX fails” was that a Greek letter “μ” became an “m”.
Recent practitioner concerns about what can go wrong in a patent office if the filer uses DOCX when filing a patent application have been tied to the USPTO. The DOCX failure reported in this blog article was not, however, at the USPTO – it was in the ePCT system.
I should emphasize that the way WIPO has pursued character-based patent application filing is night-and-day different from the way that USPTO has pursued it. WIPO has consistently been thoughtful about character-based filing and has gone to great lengths to try to protect applicants from unintended harms. In contrast, USPTO has made many wrong choices about character-based filing, choices which disregard the concerns of applicants and practitioners.
It is impossible to overstate how careful WIPO was, from the outset, about trying to pay attention to applicants’ concerns. To give just one example among many of WIPO being thoughtful about such concerns, from the earliest days of character-based filing in ePCT, it has been possible for the applicant to provide what is called a “pre-conversion format” application file. The idea from the earliest days has been that if it were to be discovered that something had gone wrong in the conversion from the applicant’s own trusted format into the XML-based PCT format, the applicant would be able to point to the pre-conversion file so that everyone could see what the applicant intended the patent application to say.
Which brings us around to my Greek letter “μ” that became an “m” as you see in the image at the beginning of this blog article. In the ePCT system, the ultimate goal for receiving characters from the applicant is that the filer provides an XML file, formatted according to something called “Annex F”. In the ePCT system, one of the permitted ways to e-file is for the applicant to literally upload that XML file. Given that most would-be filers do not have a word processor that natively works in Annex F XML, it is understandable that the folks at WIPO provide a DOCX-to-XML converter. The idea is that you as a filer could author your PCT patent application in some word processor (for example Google Docs or Libre Office) that is able to export DOCX format. Or maybe you as a filer would pick Microsoft Word (which natively stores in its own version of DOCX format) as the way to author your PCT patent application, in which case there is no need for you to “export” the application into DOCX format because with Microsoft Word, the native storage format is (a variant of) DOCX.
And then you upload your exported DOCX file (if you used some non-Microsoft product), or your natively authored DOCX file (if you used Microsoft Word) into the ePCT DOCX-to-XML converter.
And then maybe you file your PCT patent application in ePCT.
Let’s review why you might do all of this DOCX stuff, depending on which patent office you are filing your patent application in.
If you are filing DOCX at the USPTO, you are doing it because the USPTO plans to charge you a $400 penalty if you try to choose some format other than DOCX (PDF, for example) that will “control”.
If you are filing DOCX at ePCT, you are maybe doing it because it will reduce your international filing fee by 100 Swiss Francs. But you get to include the “pre-conversion format” file if you wish.
WIPO uses a carrot. USPTO uses a stick.
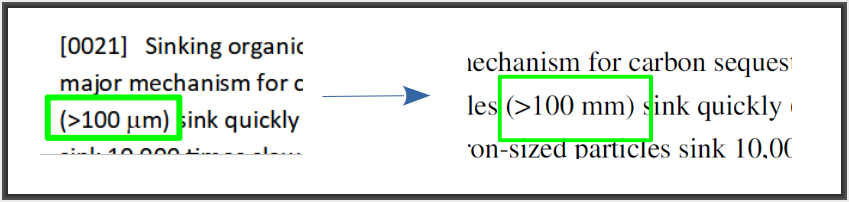
So let’s talk about my Greek letter “μ” that became an “m”. In this case, on October 22, 2022 I had authored my PCT patent application in Libre Office. Its native file format is ODT. (I would have been delighted if ePCT had offered an ODT-to-XML converter.) I clicked in Libre Office to ask it to export the ODT file into DOCX format, which it did. I then uploaded the DOCX file into the ePCT DOCX-to-XML converter. It gave me back a PDF file that allowed me to see the results of the ePCT conversion of DOCX to XML. I was astonished to see three types of DOCX failure. The first was that my Greek letter “μ” became an “m”. Here is the original (Libre Office) rendering:

And here is what I was gobsmacked to see in the ePCT DOCX-to-XML rendering:

Another baffling DOCX fail was the coinage of a new word “howsize”:

When I saw this new word “howsize” that had been rendered in my to-be-filed application in ePCT, I went back to look at the original file in Libre Office. Here it is:

I said that there were three DOCX failures that day in the ePCT DOCX-to-XML conversion process. The third one was more subtle. Can you see it?

Yes what turned out is that every time a word got hyphenated at the end of a line, the DOCX-to-XML converter inserted a spurious double-space (instead of the original single space) before the hyphenated word.
When I saw all of this going wrong with the DOCX conversion in the ePCT system, I was reminded that unlike the USPTO, WIPO is nice about this. With the USPTO, the plan is that your punishment if you don’t play by USPTO’s rules is that you have to pay $400 extra. With WIPO, if you see the DOCX conversion taking some unexpected turn, you have two paths available:
-
- You can just choose to drop your DOCX plans and file in PDF, in which case there is no $400 penalty you will have to pay. It is just that the 100 Swiss Franc filing-fee reduction won’t happen. You will just pay the regular filing fee.
- You can file the DOCX-based application (perhaps after fiddling with your word processor file to try to fix the DOCX fails) and provide the pre-conversion format file, with the idea that the pre-conversion file would probably protect you if it were to turn out that there was also some other DOCX fail that you did not detect at filing time but only discovered later. (And if you choose this path, you get the 100 Swiss-Franc filing fee reduction.)
I first attacked the problem that the ePCT DOCX-to-XML converter had changed my Greek letter “μ” to an “m”. It is easy enough to see (from a computer programming point of view) how this went wrong in the ePCT DOCX-to-XML converter. The folks at WIPO designed their DOCX-to-XML converter on the assumption that the applicant must surely be using Microsoft Word. This is the same assumption that the folks at the USPTO made when they designed their DOCX-to-PDF rendering engine.
What people need to understand is that if you are a patent office and if you set a goal of having an engine that receives DOCX files and converts them to XML or renders them as PDF, you are facing a moving target. Every time that Microsoft makes yet another “extension” to the version of DOCX in which Microsoft Word stores its files, you as a patent office have to make corresponding changes to the code of your DOCX engine.

For US applicants and practitioners, the scary thing is that USPTO’s DOCX-to-PDF rendering engine is, by Director Vidal’s own admission, a constantly changing body of (proprietary) code. See this quotation (at right) from the December 19, 2022 Director’s Blog where she admits that by now it has been necessary for the DOCX proponents within the USPTO to update the engine seventeen times. The USPTO engine will, necessarily, need to be updated at various unpredictable times in the future, driven by things like (a) Microsoft adding more extensions to Microsoft Word and (b) users reporting newly discovered rendering failures from the USPTO engine (for example failures discovered at litigation time).
My situation is that in my firm, we don’t use Microsoft Word. We use Libre Office. What I did on October 22, 2022 was “exporting” my ODT file into DOCX format.
And what is quite clear from the two screen shots above (the Greek letter “μ” in the “before” screen shot, and the Roman letter “m” in the “after” screen shot) is that the folks at WIPO who designed their DOCX-to-XML converter were not designing it to handle the version of DOCX that comes from Libre Office. They were designing it to handle the version of DOCX that comes from Microsoft Word.
On October 22, 2022, I got to work trying to figure out how to overcome this deficiency in the ePCT DOCX-to-XML converter. Eventually I stumbled upon a workaround. I went back to Libre Office and rummaged through the world of Unicode symbols, trying one variant of Greek letter “μ” after another in my ODT file. With each try, I then exported my ODT file into DOCX format, and then uploaded the DOCX file into ePCT, and viewed the rendered PDF file. Eventually by trial and error I found one particular variant of Greek letter “μ” that survived unscathed through the DOCX-to-XML conversion process.
The next challenge was the problem that the DOCX-to-XML converter in ePCT had coined a new word “howsize” and stuck it into my to-be-filed PCT application. (See the before-and-after screen shots above.) Again I went back to Libre Office to look at my ODT file. What seemingly harmless formatting code in Libre Office had somehow caused this explosion in the ePCT DOCX-to-XML converter so that a new word “howsize” got created?
In Libre Office, I scrutinized the paragraph involved. I saw what I recall may have been a “non-breaking space” that had gotten into the Libre Office file as an artifact of my having imported the patent application into Libre Office from a word processor file that I received from a client who was using some word processor that was not Libre Office. I deleted the non-breaking space (if I am recalling it correctly) and then I exported the ODT file into DOCX, and uploaded the DOCX into ePCT, and the crazy word “howsize” went away.
You will recall that there was a third category of DOCX fail for this effort to use DOCX with ePCT. The third category was that the ePCT DOCX-to-XML converter was inserting a spurious double-space before every hyphenated word. I despaired at trying to find a way to work around this DOCX fail in the ePCT system. I made a judgment call that this was probably not going to blow up in my face as a malpractice lawsuit against me TYFNIL. (The change of the Greek letter “μ” to an “m”, on the other hand, or the presence of the nonsense word “howsize”, if they had been discovered TYFIL, would have been much scarier.)
I went ahead and e-filed the PCT application. I provided the pre-conversion file. I accepted the 100 Swiss Francs fee reduction.
So what can we as applicants and practitioners learn from this?
A first thing to learn is that DOCX is simply unacceptable as a filing format for patent applications. The natural path for a patent office (whether you are WIPO or USPTO or any other patent office) is to “design to match Microsoft Word’s version of DOCX” rather than designing to match the version of DOCX that gets exported from Google Docs or designing to match the version of DOCX that gets exported from Libre Office.
This “designing to match Microsoft Word’s version of DOCX” actively harms those applicants and practitioners who use a non-Microsoft word processor.
This “designing to match Microsoft Word’s version of DOCX” is likewise destined to fail every time Microsoft decides to change Microsoft Word’s version of DOCX. Every patent office around the world that has crafted a DOCX-to-PDF rendering engine, or a DOCX-to-XML converter, must necessarily update that software from time to time to track the latest changes in Microsoft Word’s version of DOCX. (Note that such an update necessarily causes further uncertainty and harm to the applicants and practitioners who use Libre Office or Google Docs.)
I know exactly what will happen next at WIPO in response to this blog article. The nice folks at WIPO will invite me to share with them the DOCX file that their converter handled so badly. I will provide it to them. The nice folks at WIPO will immediately set to work trying to figure out what was wrong with their converter that it got these things wrong in handling the file that I exported from ODT format into DOCX format. And they will expand their design goals for the converter so that it will handle not only native Microsoft Word DOCX files, but also the variants of DOCX that get exported from Google Docs and Libre Office.
This will not be easy for the folks at WIPO because there is no consistency about internal formatting of DOCX files across various word processors. But they will try as hard as they can. And what are the consequences for PCT filers if this effort by the nice folks at WIPO to accommodate users of non-Microsoft word processors is not a complete success? The answer is, “no problem!” Those users can simply file in PDF just as before, without being hit with any $400 penalty. (Yes, they miss out on what would have been a 100 Swiss Franc fee reduction.)
In contrast, the folks at USPTO seem to be stubbornly plugging away at requiring filers to provide DOCX files, or paying the $400 penalty.
There’s something unclear in your discussion above. Where did the μ to m conversion occur? Did it happen when LibreOffice created the DOCX file or did it happen when WIPO converted the DOCX file into their preferred XML format? If you opened the DOCX file in LibreOffice, what did you see? If you opened the DOCX file in Google Docs, what did you see? For that matter, if you have a copy of Microsoft Word, what did you see there?
It happened when the ePCT DOCX-to-XML converter tried to convert the DOCX file into PDF and MXML.
There was nothing wrong with the DOCX file. (Nothing wrong other than, I failed to use Microsoft Word to create it.) The screen shots that you see are screen shots of the word processor rendering the DOCX file for human eyes.
Just now I opened the DOCX file in Google Docs. The Greek letter μ is a μ. There is no “howsize” problem.
Note that your very need to ask the question “what does this DOCX file look like if you open it with software X instead of software Y?” proves my point about DOCX being the wrong answer as a way to file patent applications!
I still find it hilarious that the PTO doesn’t want you to submit a pdf file – they want you to submit a docx file, which THEY proceed to convert into, guess what, a pdf file.
What you find to be hilarious, I find to be scary. The professional liability risks of playing by USPTO’s rules are profound.
Carl, is there any chance that WIPO will consider introducing an ODT-to-xml converter?
If the DOCX file is rendered correctly in/by LibreOffice and Google Docs and perhaps also in Microsoft Word, is it fair to say that the problem is in DOCX? Or is it perhaps in the conversion to XML?
It seems true that an ODT-to-XML converter is the solution and would address all concerns about vendor lock-in and about preferential treatment of certain commercial software suppliers.
One way to describe the problem is that the problem is in the ePCT DOCX-to-XML converter. Namely that the designer of the ePCT DOCX-to-XML converter was “designing to match Microsoft Word’s flavor of DOCX”. Another way to describe the problem is that the designer of the ePCT DOCX-to-XML converter failed to design to match the variety of DOCX that is exported by Libre Office. But the first real problem, correctly understood, is for the patent offices to mistakenly assume that there is some single format called DOCX. In fact there are as many varieties of DOCX as there are word processor makers (probably more). And the second real problem is that you can take any particular DOCX file and open it in any of several word processors and render it in any of several patent office engines, and you will see page breaks in non-identical places, hyphenations in non-identical places, and disasters like a Greek letter μ becoming an m.